2.3 内存层级
同CPU一样,GPU也有不同层级的内存。越靠近核心的内存速度越快,但容量越小;反之,越远离核心的内存速度越慢,但容量较大。
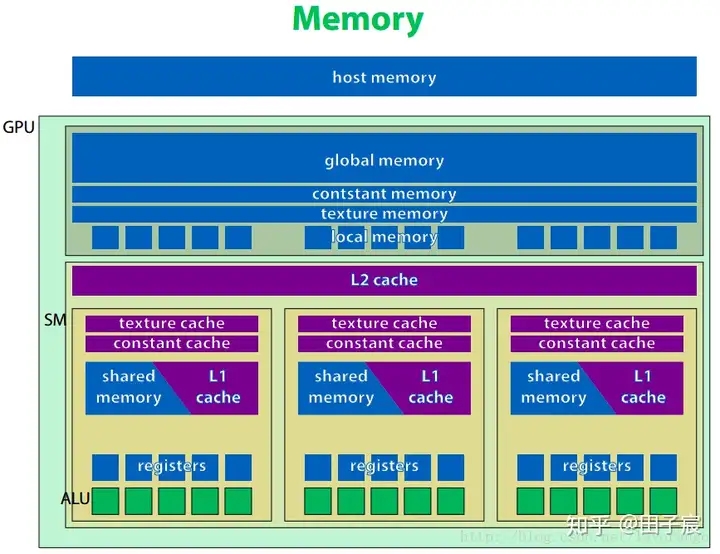
上图是NVIDIA设备的硬件示意图。
最上方是主机端内存(host memory),指的就是我们常说的内存。一般主机端内存通过PCI-E总线与设备端内存交换数据。数据交换的速度等于PCI-E总线的速度。
全局内存(global memory) 、常量内存(constant memory)、纹理内存(texture memory)、本地内存(local memory)。都位于GPU板上,但不在片内。因此速度相对片内内存较慢。 常量内存和纹理内存对于GPU来说是只读的。
GPU上有 L2 cache和 L1 cahce。其中L2 cache为所有流处理器簇(SM)共享,而L1 cache为每个SM内部共享。这里的cache和CPU的cache一样,程序员无法对cache显式操纵。
纹理缓存和常量缓存在SM内部共享,在早期1.x计算能力的时代,这两种缓存是片上唯一的缓存,十分宝贵。而当Fermi架构出现后,普通的全局内存也具有了缓存,因此就不那么突出了。
共享内存(shared memory, SMEM) 具有和L1缓存同样的速度,且可以被程序员显式操纵,因此经常被用作存放一些需要反复使用的数据。共享内存只能在SM内共享,且对于CUDA编程模型来说,即使线程块被调度到了同一个SM内也无法互相访问。
GPU的寄存器(registers) 和CPU不一样,其空间非常巨大,以至于可以为每一个线程分配一块独立的寄存器空间。因此,不像CPU那样切换进程时需要保存上下文,GPU只需要修改一下寄存器空间的指针即可继续运行。所以巨大的寄存器空间,使得GPU上线程切换成为了一个几乎无消耗的操作。 不过有一点需要注意,寄存器的空间不是无限大的。如果线程数过多,或一个线程使用的寄存器数量太多,多出来的数据会被保存到缓慢的本地内存上,影响程序速度,需要注意。
这里想强调一下共享内存。 共享内存在物理上是一个个存储体组成的。如果在访问时没有出现冲突,则可以实现高速的访问。但如果出现了冲突(如对某一个存储体的原子操作),则不仅仅当前线程束会发生串行化,而且会导致其他线程束无法被调度(存疑,待考证)。
以上是从硬件的角度解读了一下GPU的内存层级。从编程角度来看,CUDA的线程网格、线程块、线程与各个内存见的关系如下图:
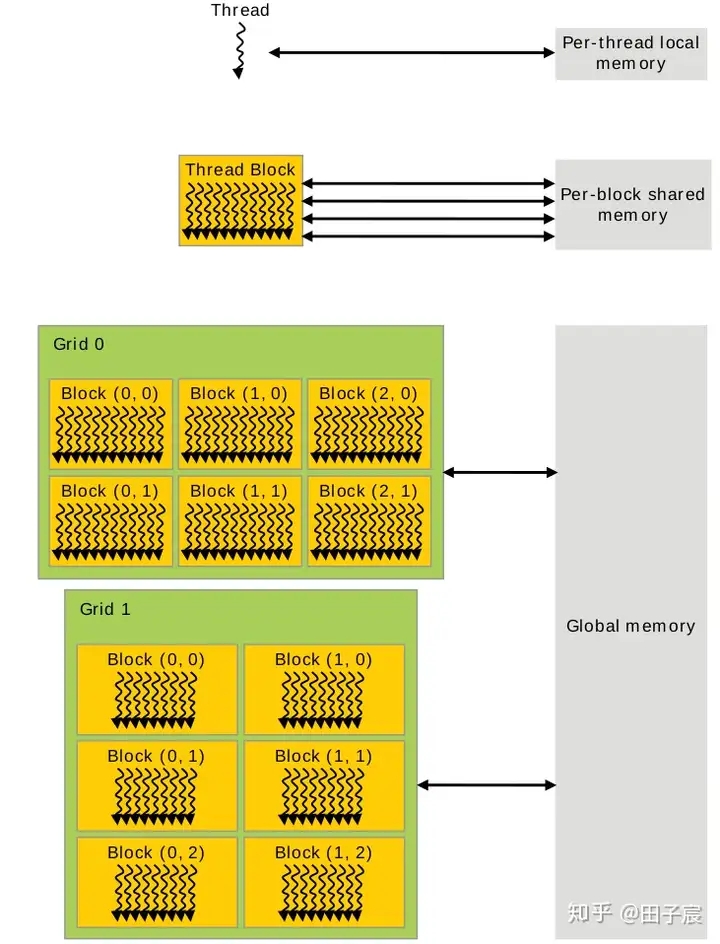
寄存器和本地内存绑定到了每个线程,其他线程无法访问。
同一个线程块内的线程,可以访问同一块共享内存。注意,即使两个线程块被调度到了同一个SM上,他们的共享内存也是隔离开的,不能互相访问。
网格中的所有线程都可以自由读写全局内存。
常量内存和纹理内存只能被CPU端修改,GPU内的线程只能读取数据。
Last updated